The Mean Squared Error (MSE) formula is a fundamental metric in statistical and machine learning analysis. It quantifies the average squared differences between predicted values and the actual values. Understanding MSE is crucial for anyone working with predictive models because it serves as a primary indicator of model performance. This article aims to demystify MSE, shedding light on its practical applications and offering expert insights for leveraging this metric in model assessment and refinement.
Understanding Mean Squared Error
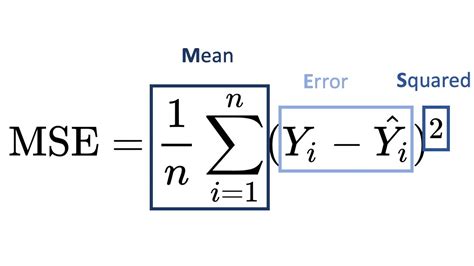
Mean Squared Error (MSE) is calculated as the average of the squared differences between predicted values (ŷ) and actual observed values (y). The formula is given as follows:
MSE = (1/N) * Σ(y - ŷ)²
Where:
- N is the number of data points
- Σ represents the summation
- y is the actual observed value
- ŷ is the predicted value
This measure is highly valued for its ability to penalize larger errors more than smaller ones, thereby encouraging models to minimize not just errors but the squared magnitude of those errors.
Key Insights
- MSE provides a clear picture of the model's predictive accuracy.
- Its squared nature penalizes larger errors more, incentivizing model optimization for smaller, squared error differences.
- Utilize MSE for comparing different models to determine which offers the best predictive performance.
Application of MSE in Model Evaluation
MSE plays a pivotal role in the evaluation of regression models. When comparing the performance of two regression models, a lower MSE value indicates a model that is better at predicting outcomes with higher precision. For example, suppose we have two linear regression models predicting house prices based on square footage. If Model A has an MSE of 200,000 and Model B has an MSE of 100,000, Model B is clearly outperforming Model A because its predictions deviate less from actual prices, on average.
In practical applications, MSE is often normalized by dividing by the number of observations to yield a per-sample measure, making it easier to compare models across different datasets and scales.
Advanced Uses of MSE
Beyond its primary use in model evaluation, MSE is instrumental in hyperparameter tuning. When using techniques like gradient descent for model optimization, MSE serves as the objective function. By minimizing MSE, algorithms adjust model parameters to reduce the error between predicted and actual values. For instance, when developing neural networks, MSE is commonly employed as the loss function during training to guide the learning process towards more accurate predictions.
Moreover, MSE can be decomposed into bias and variance to further diagnose model performance issues. A high MSE might indicate a model with either high bias (underfitting) or high variance (overfitting). Decomposing MSE helps in determining the exact source of error and allows for targeted model improvements.
How is MSE different from Mean Absolute Error (MAE)?
While MSE squares the error term, MAE takes the absolute value. MSE penalizes larger errors more severely, making it useful for identifying and minimizing significant discrepancies, whereas MAE provides a more straightforward, less sensitive measure.
MSE is a powerful and indispensable tool in the arsenal of data scientists and statisticians. By understanding and effectively utilizing MSE, one can build and refine predictive models that deliver accurate, reliable, and optimal predictions. Whether you are in the initial stages of model development or tuning an existing model, MSE remains a cornerstone metric for enhancing performance and ensuring high-quality outcomes.


